スーパースカラCPUとは?命令並列化の仕組み・特徴と性能解説
スーパースカラCPUの仕組みと性能を図解で解説。命令並列化・ディスパッチャの役割や利点、設計上の注意点まで初心者にも分かる詳解。
スーパースカラCPUの設計は、1つのCPUコア内で命令レベル並列(Instruction-Level Parallelism: ILP)を実現し、同じクロックレートでより多くの作業を行えるようにするアプローチです。簡単に言うと、CPUが複数の命令を同時に実行(これを一般に命令ディスパッチや発行(issue)と呼びます)し、1クロックサイクル中に複数の命令を実行することを目指します。各機能ユニットとは、演算論理ユニット(ALU)、浮動小数点ユニット(FPU)、ビットシフタ、乗算器など、CPUコア内の実際の実行リソースに対応するものです。
画像ギャラリー
2 画像
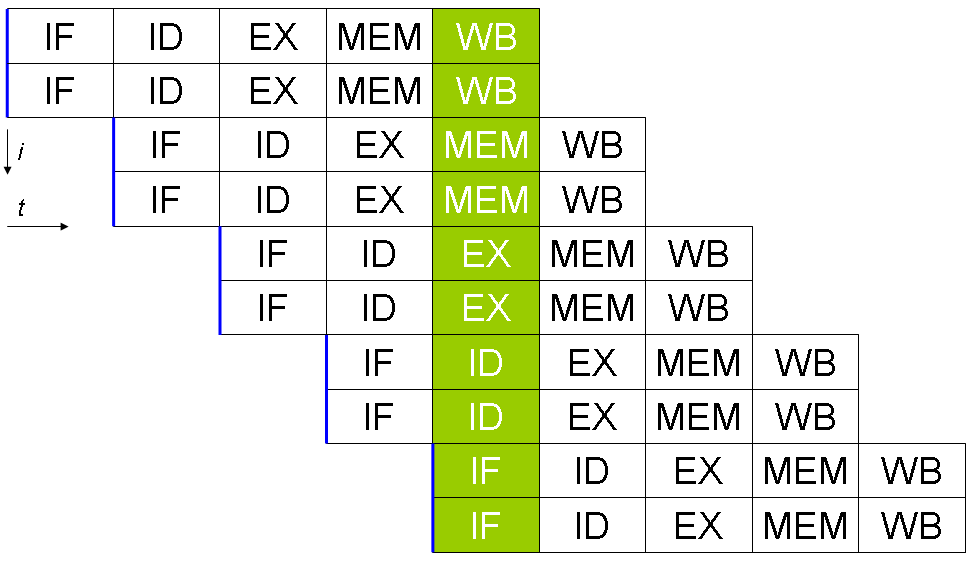
基本的な仕組み
スーパースカラCPUでは、命令のフェッチ(読み出し)→デコード→ディスパッチ(発行)→実行→コミット(結果確定)というパイプラインの流れの中で、1クロックに複数の命令を同時に扱います。ほとんどのスーパースカラCPUはパイプライン化されていますが、パイプライン化されていないスーパースカラや、その逆(パイプライン化はされているがスーパースカラではない)も理論上は存在します。パイプライン化とスーパースカラは別個の設計上の特徴であり、組み合わせて用いられることが多いです(例:同じクロックで複数命令を発行し、それぞれが多数段のパイプラインを通る)。
スーパースカラを支える要素
- 命令の読み出し順序管理:命令は命令表から出てきます。並列実行のために複数命令を同時にフェッチできる仕組みが必要です。
- 依存関係解析とリネーミング:CPUハードウェアは、どの命令がどのデータに依存しているかを調べ、データ依存(RAW/WAR/WAW)を管理できる必要があります。これにはレジスタリネーミングが用いられます。
- 同時読み出しと同時発行:1クロックサイクルで複数の命令を読み出すことが可能で、かつ利用可能な実行ユニットに割り当てられる必要があります。
スカラープロセッサでは各命令が一般に1つまたは2つのデータ項目を扱うのに対し、ベクトルプロセッサ(SIMD)は1つの命令で多くのデータ項目を並列処理します。スーパースカラはこの両者の中間に位置し、
- 各命令は通常1つのデータ項目を処理し、
- 各CPUコアの内部には重複する機能ユニットが複数存在し、独立した命令が同時に異なるユニットで実行される
命令ディスパッチと実行パイプライン
スーパースカラCPUでは、命令ディスパッチャがメモリから命令を読み込み、並列実行可能な命令を決定して、CPU内部の複数の重複機能ユニットに命令をディスパッチします。実際の実装では以下のような段階があり、それぞれが性能に影響します。
- フェッチ:幅(fetch width)だけ命令を取り出す。
- デコード:複数命令を同時にデコードして発行候補にする。
- リネーミング/依存解析:レジスタリネーミングで仮想的な依存を排除し、真のデータ依存のみを残す。
- 発行(issue):実行可能な命令を空いている実行ユニットに割り当てる。インオーダーまたはアウトオブオーダー発行がある。
- 実行:ALU/FPU/ロードストアユニットなどで演算・メモリアクセスを行う。
- コミット(完了):命令の結果を順序どおりに確定し、例外処理や分岐の状態を整える。
性能向上のための代表的技術
- アウト・オブ・オーダー実行(OoO):命令の実行順序をプログラム順序から変えて、データが揃った命令から先に実行することでユニットの稼働率を高める。
- レジスタリネーミング:名前による(仮想的な)依存を排除し、不要な待ちを減らす。
- 高精度な分岐予測:分岐ミスによるパイプラインフラッシュを減らすことは、スーパースカラの性能に直結します。
- ロード/ストアキュー、メモリ依存チェッカ:メモリアクセスの順序を管理して依存関係を解決する。
- Tomasuloアルゴリズム、再順序バッファ(ROB):ハザードを動的に管理してアウト・オブ・オーダー実行を支援します。
- マルチポートあるいは複数命令同時読み出し:命令キャッシュやデコーダのスループットを高める。
制約と課題
スーパースカラ設計は単純に幅を広げればよいわけではなく、いくつかの限界やトレードオフがあります。
- 依存関係の存在:プログラムに内在するデータ依存や制御依存は、並列化の上限を決めます(ILPには自然な上限があるため、幅を増やしても効果が薄まることがある)。
- 分岐予測ミスやキャッシュミス:これらが発生するとパイプラインの複数スロットが無駄になり、幅の拡張効果を打ち消す。
- 構造ハザード:実行ユニットやポートが不足すると、同時発行できない。
- 電力と設計複雑性:幅を広げるとハードウェア資源、配線、クロック分配が増え、消費電力と設計コストが上がる。
- メモリ壁問題:メモリアクセス遅延(メモリレイテンシ)がボトルネックになりやすい。
スーパースカラと他の並列化技術の違い
スーパースカラは単一コア内での命令並列化(ILP)を狙う技術です。対照的に、SIMD(ベクトル)命令は1命令で複数データを処理するデータ並列(DLP)です。さらに、SMT(Simultaneous Multithreading)は同一コアで複数スレッドの命令を同時に実行してユニットのスループットを向上させます。マルチコアはコア数を増やしてスレッド並列性(TLP)を確保するアプローチです。これらは相互に補完可能で、多くの最新CPUはスーパースカラ+アウトオブオーダー+SMT+SIMDを組み合わせています。
代表的な実装例と数値
2000年代以降の多くの汎用CPUはスーパースカラ設計を採用しています。設計によって幅(同時発行できる命令数)は異なり、典型的には2〜8ウェイ程度が多く、サーバ向けやハイエンドCPUではさらに広い幅を持つ設計もあります。例として、ある典型的なスーパースカラCPUは最大4つのALU、2つのFPU、2つのSIMDユニットを含むことがありました。重要なのは、ディスパッチャがすべてのユニットを常時ビジー状態にできるかどうかで、できなければ実効性能(IPC: Instructions Per Cycle)は期待より低くなります。
まとめ
スーパースカラはCPU内部で命令レベルの並列性を引き出す重要な手法であり、パイプライン化、依存解析、リネーミング、分岐予測、アウト・オブ・オーダー実行など複数の技術と組み合わせて高性能化を実現します。とはいえ、データ依存や分岐、メモリ遅延といった制約により、幅の無制限な拡張は現実的ではなく、設計は性能、消費電力、実装コストのバランスを取る必要があります。最新の汎用CPUはこれらを複合的に取り入れ、できるだけ高い命令スループットを達成しています。
参考として、スーパースカラー技術は、CPUコアのいくつかの特徴によってサポートされています。設計上は、命令ディスパッチャの精度を向上させ、複数の機能ユニットを常にビジー状態に保つことが重要です。


制限事項
SuperscalarのCPU設計における性能向上は、2つのことによって制限されています。
- 命令リストの組み込み並列性のレベル
- ディスパッチャとデータの依存性チェックの複雑さと時間的なコスト。
通常のスーパースカラCPU内で無限に高速な依存関係チェックを行っても、命令リスト自体が多くの依存関係を持っていれば、性能向上の可能性も制限されてしまうため、コード内に組み込まれている並列性の量も制限の一つとなります。
ディスパッチャの速度がどれだけ速くても、同時にディスパッチできる命令数には現実的な限界があります。ハードウェアの進歩により、CPUコアあたりの機能ユニット(例: ALU)の数は増えるでしょうが、命令の依存性をチェックする問題は、達成可能なスーパースカラースピッチングの制限がやや小さい限界まで増加します。-- 同時にディスパッチされる命令数は5~6個のオーダーになると思われます。
代替品
- 同時マルチスレッド(Simultaneous Multithreading):SMTと略されることが多いが、これはスーパースカラCPUの全体的な速度を向上させるための技術である。SMTでは、複数の独立したスレッドを実行することで、最新のスーパースカラプロセッサ内で利用可能なリソースをより有効に利用することができます。
- マルチコアプロセッサ:スーパースカラプロセッサは、冗長化された複数の機能ユニットがプロセッサ全体ではない点でマルチコアプロセッサとは異なる。1つのスーパースカラプロセッサは、ALU、整数乗算器、整数シフタ、浮動小数点演算装置(FPU)などの高度な機能ユニットで構成されています。多数の命令を並列に実行できるように、各機能ユニットのバージョンが複数ある場合もある。これは、1コアにつき1スレッドの複数のスレッドからの命令を同時に処理するマルチコアプロセッサとは異なります。
- パイプライン・プロセッサ:スーパースカラ・プロセッサも、複数の命令を様々な段階で同時に実行できるパイプライン・プロセッサとは異なります。
様々な代替技術は互いに排他的なものではなく、1つのプロセッサに組み合わせて使用することができます(そして頻繁に使用されます)。マルチコアプロセッサの中には、ベクトル機能を持つものもあります。
関連ページ
- 並列計算
- 命令レベルの並列性
- 同時マルチスレッド (SMT)
- マルチコアプロセッサ
質問と回答
Q:スーパースカラ技術とは何ですか?
A:スーパースカラ技術とは、基本的な並列計算の一形態で、複数の実行ユニットを同時に使用することにより、1クロックサイクルで複数の命令を処理することができます。
Q: スーパースカラ技術はどのように動作するのですか?
A: スーパースカラ技術では、命令が順番にプロセッサに入ってきて、実行中にデータの依存関係を探し、各クロックサイクルで複数の命令をロードします。
Q:スカラプロセッサーとベクトルプロセッサーの違いは何ですか?
A:スカラプロセッサーでは、命令は通常1つか2つのデータを同時に扱うのに対し、ベクトルプロセッサーでは、命令は通常多くのデータを同時に扱う。スーパースカラ・プロセッサは、1つの命令が1つのデータ項目を処理しますが、複数の命令が同時に実行されるため、プロセッサが一度に扱うデータ項目が多くなります。
Q: スーパースカラ・プロセッサにおいて、正確な命令ディスパッチャはどのような役割を果たすのでしょうか?
A:正確な命令ディスパッチャは、スーパースカラ・プロセッサにとって非常に重要なもので、実行ユニットが常に必要と思われる作業で忙しいことを保証します。もし命令ディスパッチャが正確でなければ、一部の処理を放棄することになり、スケーラープロセッサと同じ速度にならなくなってしまうからです。
Q: 通常のCPUがスーパースカラ化したのは何年か?
A:2008年に通常のCPUはすべてスーパースカラになりました。
Q: 通常のCPUには、何個のALU、FPU、SIMDユニットがあるのですか?
A:通常のCPUでは、ALUが4個、FPUが2個、SIMDが2個まで可能です。
関連項目
著者
AlegsaOnline.com スーパースカラCPUとは?命令並列化の仕組み・特徴と性能解説 Leandro Alegsa
URL: https://ja.alegsaonline.com/art/95080