ASCIIとは?文字コードの定義と歴史、128文字の仕組みをやさしく解説
ASCIIの定義と歴史、128文字の仕組みをやさしく解説。コード表や制御文字、8ビット表現の由来まで初心者にもわかる入門ガイド。
ASCII(一般には「アスキー」と発音される)は、コンピュータでテキストを扱うための基本的な文字コードのひとつです。ASCIIは American Standard Code for Information Interchange の略称で、1960年代に電信やテレタイプ端末で使われていた符号体系をもとに標準化され、1963年に最初の版が発表されました。その後改訂を経て広く普及し、現代の文字コード体系の基礎となっています。
画像ギャラリー
1 画像
ASCIIの仕組み — なぜ「128文字」なのか
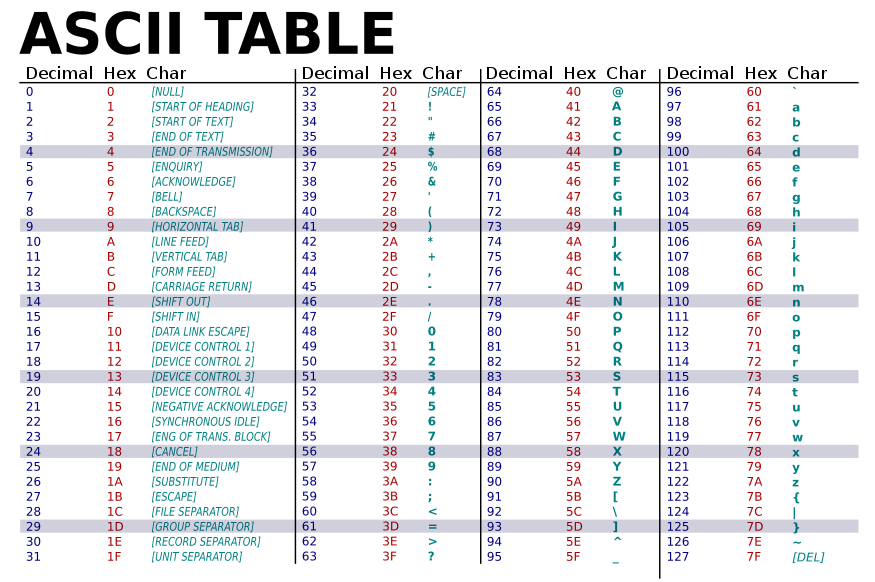
ASCIIは7ビット(0〜127の数値)で文字を表すコードで、合計で128種類のコードポイントが定義されています。一般に「印刷可能な文字」はコード値32(スペース)から126(チルダ ~)までに収められており、ここには英字(abc, ABC)、数字(0–9)、句読点や記号(? & ! など)が含まれます。残りの0〜31および127は「制御文字」と呼ばれ、テキストの表示そのものではなく、送受信や端末制御のための命令を表します(例:NUL、BEL、HT(タブ)、LF(ラインフィード、10)、CR(キャリッジリターン、13)、ESCなど)。これらのうち多くは現代の用途では本来の目的で使われないこともありますが、改行やタブなど一部は現在も重要です。
数値表現と例
ASCIIコードは十進(10進)、十六進(16進)、二進のいずれでも表せます。たとえば大文字の「A」は十進で65、16進で0x41、7ビット二進で1000001です。コンピュータ内部やファイルでは多くの場合8ビット(1バイト)単位で扱うため、表示や伝送の際には先頭に0を付けて01000001のように8ビット表記されることが一般的です。
過去にはシリアル通信やモデム伝送で誤り検出のために追加のパリティビット(8ビット目)を付けて送ることが多く、これが「8ビットで扱う」という誤解を生む原因にもなりました。重要なのは、ASCIIそのものの定義は7ビットであるという点です。
制御文字と書式の違い
ASCIIには太字や斜体といった書式情報は含まれていません。テキストの見た目(フォントや装飾)は表示側のアプリケーションやプロトコルで別途扱われます。ASCIIの制御文字は、端末やプリンタの動作を制御するために設計されたもので、たとえばベル(BEL=7)はビープ音を鳴らす、CR(13)とLF(10)は行の位置を戻す/改行する、ESC(27)は後続のエスケープシーケンスでより複雑な制御を指定する、などの用途があります。
ASCIIの拡張と現代の互換性
ASCIIの範囲(0–127)は非常に基本的なため、国際化やアクセント付き文字、記号の追加などを目的に多くの「拡張ASCII」コードページ(ISO-8859シリーズやWindows-1252など)が登場しました。これらは8ビットをフルに使い、128〜255の領域に追加文字を割り当てます。
さらに現代ではUnicode(UTF-8など)が世界中の文字を扱う標準となっていますが、UTF-8はASCIIの0〜127のコードポイントをそのまま同じバイト列で表すため、ASCIIとの下位互換性が保たれています。つまり、ASCIIで書かれたプレーンテキストは多くの場合そのままUTF-8テキストとしても正しく扱えます(プレーンテキストという言い方はこの互換性を指すことが多いです)。
まとめ(ポイント)
- ASCIIは「American Standard Code for Information Interchange」の略で、1960年代に標準化された文字コード。
- 定義は7ビットで、128(0〜127)のコードポイントを持つ。印刷可能文字は32〜126、0〜31と127は制御文字。
- 太字や斜体などの書式情報は含まれないため、書式は別の仕組みで制御する必要がある。
- 8ビットバイトやパリティを使って伝送されることはあるが、ASCII自体は7ビットが基本。UTF-8はASCIIと互換性がある。

拡張アスキー
ASCII にはダイアクリティカル(ドイツ語の母音の上にあるドット(ウムラウト)やスペイン語の「ñ」のための「n」の上にあるチルダ(~)のように、文字に追加されるマーク)がありません。これは英語専用のもので、他のほとんどの言語ではうまく機能しません。他の言語から借りてきた英単語の中には、resumé のようにこれらのマークを使うものもあります(付録:ダイアクリティカルを持つ英単語を参照)。
このため、一部のシステムでは7ビットではなく8ビット(フルバイト)を使用するようになりました。8ビットを使用するシステムのための適切な名前は、拡張ASCIIと呼ばれています。8ビットでは256文字を使用することができます。最初の128文字はASCIIのための同じでなければならず、残りは通常アクセントが付いているアルファベット文字のために使用される、例えばÉ、È、Î、ÎおよびÜのような。これはラテンアルファベットをベースにした言語の問題を解決しますが、拡張されたASCIIシステムがすべて同じというわけではありません。ギリシャ語のアルファベットやキリル文字のような他のアルファベットは、異なる文字セットを必要とします。彼らは何千もの文字を使用しているので、中国の文字を使用しているようないくつかのシステムは、まだ動作しません。だからユニコードは、すべての言語のための1つの共通のシステムを持っているように作成されました。
標準ASCIIは、特にコンピュータソフトウェアやHTMLファイルでは、今でも一般的に使用されています。2010年まではURLの標準でした。テキストを入力するためのフィールドを持つウェブサイトでは、ASCIIテキストのみを使用することがよくあります。太字や中央揃えのテキストなどの特別なマークアップは正しく表示されません。
質問と回答
Q:ASCIIとは何ですか?
A:ASCIIはコンピュータ用の文字表で、英語のアルファベット、数字、その他の一般的な記号を使ったテキストを扱うためにバイナリコードを使用しています。
Q:ASCIIとは何の略ですか?
A:ASCIIは、American Standard Code for Information Interchangeの略です。
Q:ASCIIはいつ開発されたのですか?
A:ASCIIは1960年代に開発されました。
Q:コードには何文字が含まれていますか?
A:コードには128文字の定義があり、0から127までの数字が割り当てられています。
Q:ASCIIの1文字を表現するには何ビット必要ですか?
A:ASCII文字を表現するためには、7つの2進数(ビット)が必要です。
Q:ASCIIコンピュータのファイルは、1文字につき1バイトを使用するのですか?
A:はい、ASCIIコンピュータ・ファイルは1文字あたり1バイトを使用し、1バイトあたり8ビットを使用します。
Q:標準ASCIIは現在もよく使われているのですか?A:はい、標準ASCIIは現在でも特にコンピュータ・ソフトウェアやHTMLファイルでよく使われています。
関連項目
著者
AlegsaOnline.com ASCIIとは?文字コードの定義と歴史、128文字の仕組みをやさしく解説 Leandro Alegsa
URL: https://ja.alegsaonline.com/art/6475
出典
- robelle.com : "ASCII Character Set"
- asciitable.com : "ASCII table & description"