Zipfの法則(ジップフの法則)とは — 単語頻度とランキング分布の逆比例
Zipfの法則とは?単語頻度がランクに逆比例する驚きの規則性と応用例(言語・都市・企業)をわかりやすく解説。
Zipfの法則は経験則で、数学統計学を用いて定式化されたもので、最初に提案した言語学者ジョージ・キングスレー・ジップフにちなんで名付けられました。
Zipfの法則は、使用されている単語の大きなサンプルが与えられると、どの単語の頻度も頻度表のランクに反比例するというものです。したがって、単語番号nは1/nに比例した頻度を持っています。
このように、最も出現頻度の高い単語は、2番目に出現頻度の高い単語の約2倍、3番目に出現頻度の高い単語の約3倍の頻度で出現することになります。例えば、英語の単語のあるサンプルでは、最も頻繁に出現する単語である"the"が全単語の7%近くを占めています(100万語強のうち69,971語)。Zipfの法則に従い、2位の"of"は3.5%強の単語を占めており(36,411回)、"and"がそれに続いています(28,852回)。大規模サンプルの半分の単語を占めるには、わずか約135語しか必要ありません。
このような関係は、各国の都市の人口ランキング、企業規模、所得ランキングなど、言語とは関係のない多くのランキングにも見られる。人口別都市ランキングにおける分布の出現は、1913年にフェリックス・アウアーバッハによって初めて注目された。
なぜZipfの法則がほとんどの言語に当てはまるのかはわかっていません。
画像ギャラリー
3 画像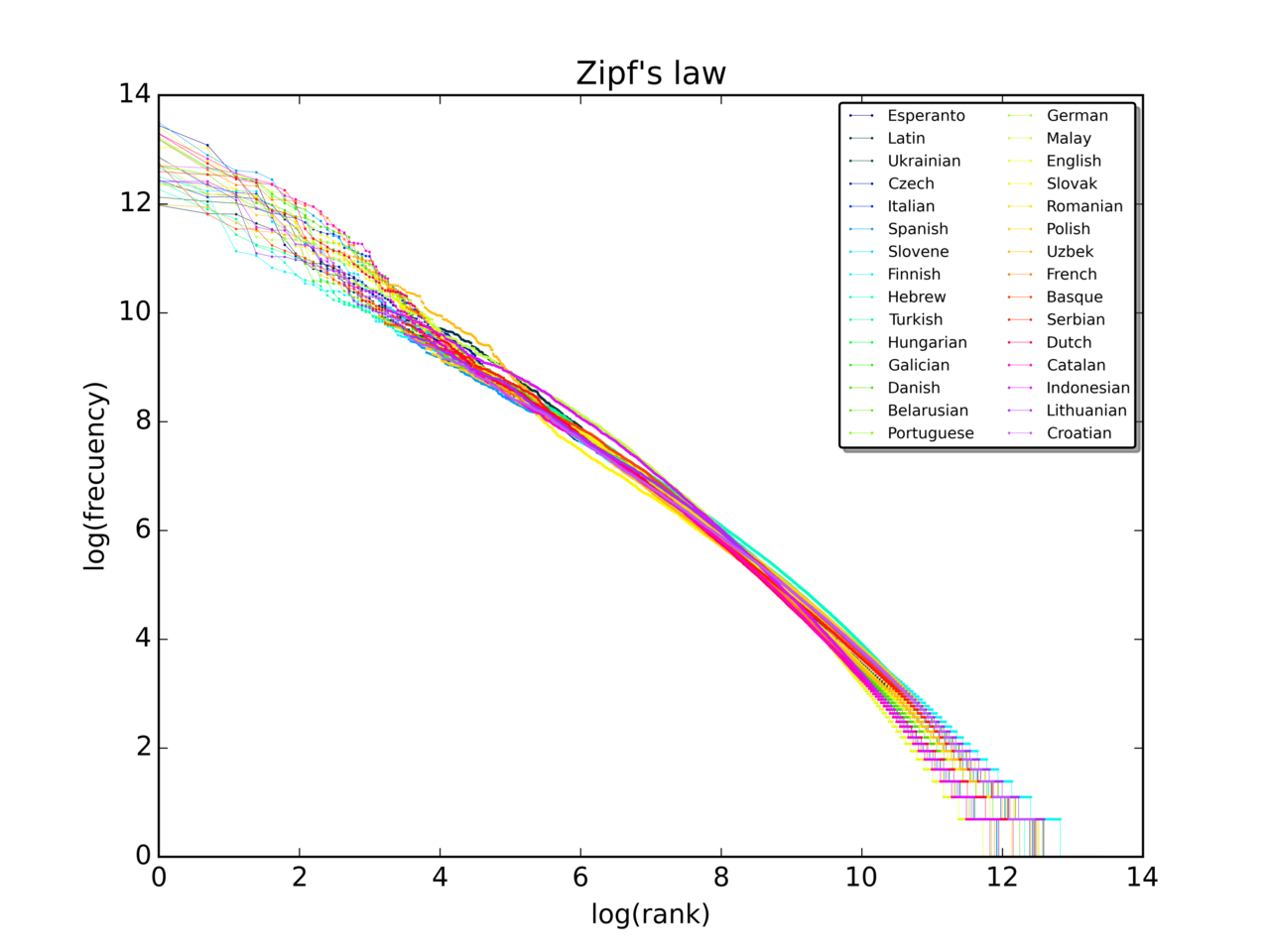


定式化(数式での表現)
一般にZipfの法則は次のように表されます。ランク r の単語の出現頻度 f(r) は
f(r) ≈ C / r^s
で表され、ここで C は正規化定数、s は指数(多くの言語コーパスでは約1に近い)です。特に s = 1 のときが古典的なZipfの法則です。ランク-頻度グラフを対数座標で描くと、Zipf則に従うデータはほぼ直線になり、その傾きが -s に相当します。
代表的な説明とモデル
- 最小努力の原理(Zipf自身の説明):話し手は単語の数を減らしたい(記憶や発話の努力を減らす)一方で聞き手は区別できる語彙を欲する。このトレードオフの結果として、頻度の高い少数の語と多数のまれな語という分布が生じる、という直観的な説明です。
- 優先的選択(Preferential attachment / Simonモデル):既に頻繁に使われている単語は今後も使われやすいという自己増殖的過程により、べき乗分布が生じるというモデルがあります(確率過程に基づく説明)。
- ランダム生成モデル(モンキータイピングなど):無作為に文字列を生成して単語として区切るような単純モデルでも近似的にZipf類似の分布が出ることが示され、完全な説明ではないものの一部の性質を説明します。
- 情報理論的説明:効率的通信を仮定すると、語の出現確率分布が特定の形(べき乗則に近い)をとるという理論的議論もあります。
派生・変種と関連法則
- Zipf–Mandelbrotの法則:実データでは低ランク部(最頻出語)でずれが生じることが多く、これを補正するためにランクに定数を加えた形 f(r) ≈ C / (r + q)^s の形が用いられます。
- Heapsの法則(語彙増加則):コーパスサイズ N に対して語彙数 V(N) が V(N) ∝ N^β (β < 1)で増えるという経験則で、Zipfの法則と密接に関連しています。概念的には、語の頻度分布(Zipf)とボキャブラリの成長(Heaps)は相互に影響します。
- パレート則(Pareto)やその他のべき乗則:Zipfはべき乗則の一例であり、経済学や都市人口分布など多くの分野で類似のスケール不変性が観察されます。
実際のコーパスでの観察と注意点
- コーパスの大きさや種類によって指数 s は1から多少ずれることがある。小さなサンプルではノイズが大きく影響する。
- 低ランク(高頻度)語と高ランク(極めてまれな語)の両端で理想的なべき乗則から外れることが多い。中間領域で比較的よく近似されることが多い。
- 統計的検定や最尤推定を用いてべき乗分布の妥当性を評価する必要があり、見かけ上の直線が必ずしも真のべき乗則の証拠とは限りません。
応用例と観測例
言語以外でもZipf類似の分布は多くの現象で見られます。例:
- 都市の人口ランキング(少数の大都市と多数の小都市)
- 企業の規模や売上分布、個人所得の上位分布
- ウェブページのアクセス頻度やソーシャルメディアでのフォロワー分布
- 生物学的配列におけるモチーフ頻度(議論は続いている)
限界と未解決問題
Zipfの法則は多くのデータに非常によく当てはまる一方で、なぜ普遍的に現れるのかについては単一の決定的な説明が存在しません。複数のメカニズム(情報理論的、進化的、確率過程)が寄与している可能性が高く、学際的な研究が続けられています。
まとめ(要点)
- Zipfの法則はランクと頻度が逆比例に近いことを述べる経験則で、言語データで特に顕著に観察される。
- 数学的にはべき乗則 f(r) ≈ C / r^s(多くの場合 s ≈ 1)で表され、対数-対数プロットで直線に現れる。
- 説明モデルはいくつか提案されているが、単一の決定的な起源は未だ確定していない。
- 都市人口や企業規模など、言語以外の分野でも類似の分布が観察され、幅広い応用と研究対象となっている。
質問と回答
Q: Zipfの法則とは何ですか?
A: Zipfの法則とは経験則の一つで、大きな標本における単語の頻度は、頻度表におけるその単語の順位に反比例するというものです。
Q: ジプフの法則を提唱したのは誰ですか?
A: ジプフの法則は、言語学者のジョージ・キングスレー・ジプフが最初に提唱しました。
Q: ジプフの法則は英単語のサンプルにおける単語頻度をどのように説明しますか?
A: ジプフの法則によると、英単語のサンプルの中で最も頻度の高い単語は、2番目に頻度の高い単語の約2倍、3番目に頻度の高い単語の約3倍の頻度で出現します。この傾向は単語のランクが下がるにつれて続きます。
Q: ある英単語サンプルの中で、最も出現頻度の高い単語は全単語の何パーセントを占めていますか?
A: ある英単語のサンプルでは、最も出現頻度の高い単語("the")は全単語の7%近くを占めています。
Q: サンプルの半分を占めるのに必要な単語の数と、その単語の出現頻度の関係は?
A: ジプフの法則によると、大きなサンプルの半分の単語を占めるのに必要な単語数は約135個です。
Q: Zipfの法則を示す他のランキングは?
A: ジプフの法則が示す単語の頻度と同じ関係が、言語とは関係のない他のランキング、例えば各国の都市の人口ランキング、企業の規模ランキング、所得ランキングなどでも見られます。
Q: 都市の人口ランキングに分布が現れることに気づいたのは誰ですか?
A:人口による都市ランキングに分布が現れることに最初に気づいたのは、1913年にフェリックス・アウエルバッハ(Felix Auerbach)です。
関連項目
著者
AlegsaOnline.com Zipfの法則(ジップフの法則)とは — 単語頻度とランキング分布の逆比例 Leandro Alegsa
URL: https://ja.alegsaonline.com/art/110649
出典
- books.google.com : P. 139