人工ニューラルネットワーク(ANN)とは?定義・仕組み・応用を分かりやすく解説
人工ニューラルネットワーク(ANN)の定義・仕組み・実用例を初心者向けに図解と事例でわかりやすく解説。応用領域や学習のポイントも短時間で理解。
ニューラルネットワーク(ANN、Artificial Neural Networkとも呼ばれる)は、生物の神経細胞から着想を得た一種のコンピュータ・ソフトウェアである。生物の脳は難しい問題を解決する能力がありますが、それぞれのニューロンは問題のごく一部しか解決することができません。同様に、ニューラルネットワークは、個々の細胞は問題のごく一部を解決することにしか責任を負わないが、望ましい結果を生み出すために協力し合う細胞で構成されている。これは、人工的に知的なプログラムを作るための一つの方法である。
ニューラルネットワークは、機械学習の一種で、学習によってプログラムが変化し、問題を解決していくものである。しかし、ニューラルネットワークの規模が大きくなればなるほど、より多くの例題が必要となり、ディープラーニングの場合、数百万から数十億の例題が必要になる。
画像ギャラリー
6 画像




基本的な仕組み(構成要素)
ニューラルネットワークは多数の人工ニューロン(ノード)を層状に並べたもので、以下の要素で構成されます。
- 入力層:外部データ(画像のピクセル値や数値など)を受け取る層。
- 隠れ層(複数あることが多い):入力を処理して特徴を抽出する層。層が深くなるほど複雑な特徴を学習できる。
- 出力層:問題の答え(分類ラベルや予測値など)を出力する層。
- 重み(weights)とバイアス(bias):ノード間の接続の強さを表すパラメータで、学習によって更新される。
- 活性化関数(activation function):ノードが受け取った総入力を変換し、非線形性を導入する関数(例:ReLU、シグモイド、tanh)。
学習の流れ(訓練)
一般的な学習プロセスは次のようになります。
- 1) 順伝播(forward pass):入力データがネットワークを通り、出力が計算される。
- 2) 損失関数(loss)で出力と正解との差を評価する。例:平均二乗誤差、交差エントロピー。
- 3) 逆伝播(backpropagation):損失を各パラメータに関して微分し、勾配を計算する。
- 4) 最適化(optimizer):勾配に基づいて重みを更新する(例:確率的勾配降下法(SGD)、Adamなど)。
- 5) この過程を複数エポック(全データを何度も繰り返す)で行い、性能を改善する。
学習時にはデータを訓練用・検証用・テスト用に分け、過学習(オーバーフィッティング)を防ぐために正則化や早期停止、ドロップアウトなどの手法が使われます。
代表的なアーキテクチャ
- フィードフォワードNN(全結合ネットワーク):最も基本的な構造。層ごとに全結合する。
- 畳み込みニューラルネットワーク(CNN):画像や映像の処理に強く、局所的な特徴を捉える畳み込み層を持つ。
- リカレントニューラルネットワーク(RNN)・LSTM・GRU:時系列データや文章など、順序情報を扱う。
- トランスフォーマー(Transformer):自己注意機構(self-attention)により並列処理が可能で、自然言語処理で高い性能を示す。
- 生成モデル(例:GAN、VAE):画像生成やデータ拡張に使われる。
主な応用例
- 画像認識・物体検出(医療画像の診断支援、顔認証など)
- 音声認識・音声合成(音声アシスタント、音声検索)
- 自然言語処理(機械翻訳、要約、感情分析、チャットボット)
- 時系列予測(株価予測、需要予測、異常検知)
- 強化学習との組み合わせ(ゲームAI、ロボット制御、自動運転の一部)
長所・短所と実運用での注意点
- 長所:複雑な非線形問題を自動で表現でき、高次元データから有用な特徴を抽出できる点。
- 短所:大量のデータと計算資源(GPU/TPUなど)が必要であり、学習過程がブラックボックスになりやすく可解釈性が低い。
- データの質と量:ラベルの誤りや偏りがあると性能に悪影響が出る。ディープモデルでは数百万~数十億サンプルが要求されることがある。
- 過学習への対策:正則化、ドロップアウト、データ拡張、クロスバリデーション、早期停止などを組み合わせる。
- 計算コスト:訓練には大量の計算時間がかかるため、ハードウェアや効率的な実装、学習率スケジューリングが重要。
- 倫理・安全性:バイアスやプライバシー、誤用に注意。モデルの挙動を評価・監査する運用が必要。
まとめ(実務的な視点)
ニューラルネットワークは強力なツールであり、適切なデータと設計、計算資源を用いれば多くの実世界問題を解決できます。一方で、データ準備、ハイパーパラメータ調整、モデルの評価・解釈、運用体制の整備など実務上の作業も多く存在します。最初は小さなモデルと適切な検証プロセスで始め、必要に応じてモデルを拡張したり、事前学習済みモデルの転移学習を活用するのが現実的な進め方です。
概要
ニューラルネットワークには、2つの考え方があります。1つ目は、人間の脳のようなもの。2つ目は、数学の方程式のようなものです。
ネットワークは、感覚器官のような入力から始まります。その後、情報はニューロンの層を通って流れ、各ニューロンは他の多くのニューロンと接続される。あるニューロンが十分な刺激を受けると、その軸索を通じてつながっている他のニューロンへメッセージを送ります。同様に、人工ニューラルネットワークは、データの入力層、分類器の1つ以上の隠れ層、および出力層を有する。各隠れ層の各ノードは、次の層のノードに接続されています。ノードは情報を受け取ると、その情報を接続されているノードにいくらかの量だけ送る。その量は、シグモイドやタンフなどの活性化関数と呼ばれる数学的関数で決定される。
ニューラルネットワークを数式のように考えると、ニューラルネットワークは、入力に適用する数学的演算のリストに過ぎない。各演算の入力と出力はテンソル(より具体的にはベクトルまたは行列)である。各層のペアは重みのリストによって接続されている。各層はいくつかのテンソルを蓄えている。層内の個々のテンソルはノードと呼ばれる。各ノードは次の層のノードの一部または全部と重みで接続されている。各ノードはまたバイアスと呼ばれる値のリストを持っている。そして、各層の値は、現在の層の値(Xと呼ばれる)の活性化関数に重みを掛けたものの外側になる。
A c t i v a t i o n ( W ( e i g h t s ) ∗ X + b ( i a s ) ) )。{displaystyle Activation(W(eights)*X+b(ias))} - {displaystyle Activation(W(eights)*X+b(ias)) 
ネットワークには、コスト関数が定義されている。損失関数は、ニューラルネットワークが割り当てられたタスクに対してどの程度うまく機能しているかを推定しようとするものである。最後に、ネットワークの重みとバイアスを変えてコスト関数の出力を最小化する最適化手法が適用される。このプロセスは「トレーニング」と呼ばれる。学習は小さなステップを1回ずつ行う。何千ものステップを経て、ネットワークは通常、割り当てられたタスクをかなりうまくこなすことができるようになる。
例
人が生きているかどうかをチェックするプログラムを考えてみましょう。脈拍と呼吸の2つをチェックし、脈拍と呼吸のどちらかがあれば「生きている」と出力し、なければ「死んでいる」と出力します。時間をかけて学習しないプログラムでは、これは次のように書かれる。
同じ問題を解く、たった1つのニューロンからなる非常にシンプルなニューラルネットワークは、次のようになります。
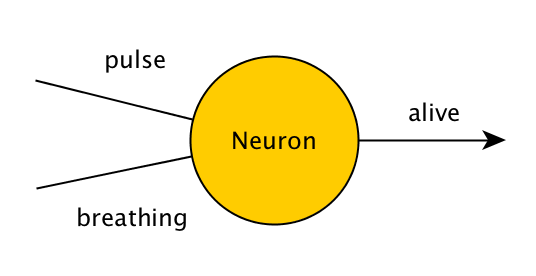
pulse、breathing、aliveの値は0か1のどちらかになり、falseとtrueを表す。したがって、もしこのニューロンに(0,1), (1,0), または (1,1)という値が与えられたら1を出力し、(0,0)が与えられたら0を出力しなければならない。ニューロンは入力に対して簡単な数学的操作を行うことによってこれを行う - 与えられた値をすべて足し合わせて、それから「バイアス」と呼ばれる自身の隠れた値を追加するのである。最初に、この隠れた値はランダムであり、もしニューロンが望ましい出力をしないなら、時間の経過とともに調整する。
(1,1)のような値を足し合わせると、1より大きい数字になってしまうかもしれませんが、出力は0と1の間にしたいのです!これを解決するには、ニューロンの計算結果がその範囲内でなくても、実際の出力を0か1に制限するような関数を適用すればよい。より複雑なニューラルネットワークでは、ニューロンに関数(シグモイドなど)を適用して、その値が0と1の間になるようにし(例えば0.66)、この値を出力が必要になるまでずっと次のニューロンに渡します。
学習方法
質問と回答
Q:ニューラルネットワークとは何ですか?
A:ニューラルネットワーク(ANNまたは人工ニューラルネットワークとも呼ばれる)は、生物学的なニューロンから着想を得た一種のコンピュータ・ソフトウェアです。個々の細胞は問題のごく一部を解決するだけですが、望ましい結果を得るために協力し合う細胞で構成されています。
Q:ニューラルネットワークは、生物の脳と比べてどうなのでしょうか?
A:生物の脳は難しい問題を解決することができますが、それぞれの神経細胞は問題のごく一部しか解決することができません。同様に、ニューラルネットワークは、個々の細胞は問題のごく一部を解決することにしか責任を負わないが、望ましい結果を生み出すために協力する細胞で構成されている。
Q:人工的に知的なプログラムを作ることができるのは、どのような種類のプログラムですか?
A:ニューラルネットワークは、機械学習の一例であり、プログラムが問題を解決するために学習しながら変化することができます。
Q:ディープラーニングを使うには、どのように訓練し、例題ごとに改良していけばよいのでしょうか?
A:ニューラルネットワークは、例ごとに学習・改善することができますが、ニューラルネットワークが大きくなればなるほど、より多くの例を必要とし、ディープラーニングの場合、数百万から数十億の例が必要になることもあります。
Q:ディープラーニングを成功させるために必要なものは何ですか?
A:ディープラーニングを成功させるためには、ニューラルネットワークの規模にもよりますが、数百万から数十億の例が必要です。
Q:機械学習は、人工知能プログラムの作成とどのような関係があるのですか?
A:機械学習は、プログラムが問題を解決する方法を学習しながら変化することを可能にするので、人工知能プログラムの作成と関係があります。
関連項目
著者
AlegsaOnline.com 人工ニューラルネットワーク(ANN)とは?定義・仕組み・応用を分かりやすく解説 Leandro Alegsa
URL: https://ja.alegsaonline.com/art/6353
出典
- newscientist.com : "Baby robot learns first words from human teacher"