マイクロアーキテクチャとは?定義と仕組み—CPU動作と命令セット(ISA)の関係
マイクロアーキテクチャの定義と動作原理をわかりやすく解説。CPUの内部構造、命令セット(ISA)との関係、性能最適化の仕組みまで図解で理解!
コンピュータ工学において、マイクロアーキテクチャ(μarchまたはuarchと略されることもある)とは、コンピュータ、中央処理装置、またはデジタル信号プロセッサの電気回路について、ハードウェアの動作を完全に記述するのに十分な記述のことである。
学者は「コンピュータ組織」という言葉を使うが、コンピュータ業界では「マイクロアーキテクチャ」と言うことが多い。マイクロアーキテクチャと命令セットアーキテクチャ(ISA)は、合わせてコンピュータアーキテクチャーの分野を構成している。
画像ギャラリー
1 画像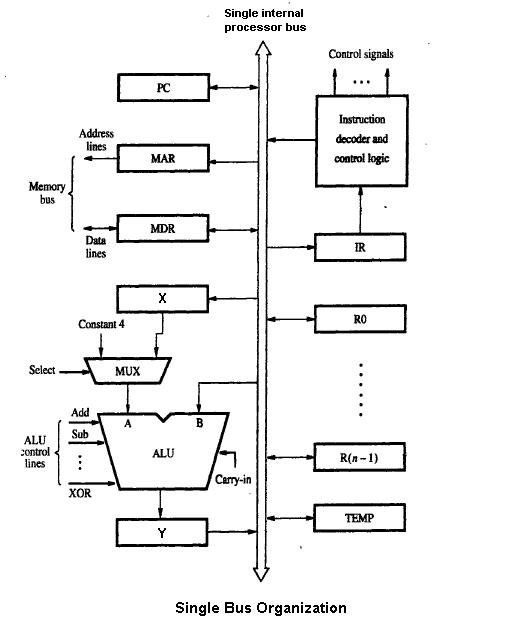
マイクロアーキテクチャとISAの違いと関係
命令セットアーキテクチャ(ISA)はソフトウェア(コンパイラやOS、アプリケーション)が見るインターフェースで、命令の意味・レジスタやメモリのモデル・例外や割り込みの振る舞いなどを規定する。一方、マイクロアーキテクチャはそのISAを実際にどのように回路で実現するかを定める設計図だ。つまり、同じISAを複数のマイクロアーキテクチャが実装できる(例:異なる世代のIntelプロセッサや、ARMの複数コア実装)。
重要な点は、ISAは「何をするか(what)」を定義し、マイクロアーキテクチャは「どうやって行うか(how)」を決める、ということだ。マイクロアーキテクチャはISAの機能を満たす限り、消費電力・性能・コスト・面積などのトレードオフに応じて異なる実装が可能である。
マイクロアーキテクチャの主要要素
- パイプライン:命令実行を複数のステージに分割し、同時並列で処理する手法(フェッチ、デコード、実行、メモリアクセス、ライトバックなど)。
- スーパースカラと並列実行:同一サイクルに複数命令を発行することでスループットを上げる設計。
- アウト・オブ・オーダ実行(OoO):プログラム順序に依存しない命令を先に実行してリソース利用を最大化する機構。レジスタリネーミングやリオーダーバッファを伴う。
- ブランチ予測:条件分岐の行き先を予測してパイプラインを空回りさせないようにする。性能に大きく寄与する。
- キャッシュとメモリ階層:L1/L2/L3キャッシュ、TLBなどを含む階層的な高速メモリ設計。キャッシュ戦略(アソシアティビティ、置換アルゴリズム)が性能に影響する。
- メモリ一貫性とコヒーレンシ:マルチコア環境でのデータの整合性を保つプロトコル(MESIなど)。
- 入出力とインターコネクト:コア間やコアとメモリコントローラを結ぶバス/ネットワーク設計。
- 制御ロジックとマイクロコード:命令を直接ハードウェアで解釈する方式(ハードワイヤード)や、複雑命令をマイクロコードで実装する方式がある。
設計上のトレードオフ
マイクロアーキテクチャ設計は複数の相反する目標のバランス取りである。主なもの:
- 性能(スループット/レイテンシ):深いパイプラインや多数の並列発行で性能向上が可能だが、パイプラインハザードやブランチミスのコストが増す。
- 消費電力と発熱:高性能化はしばしば高消費電力を招く。モバイル向けでは電力効率が最優先される。
- 回路面積(コスト):大きなキャッシュや多数の実行ユニットはダイサイズを増やす。
- 設計の複雑さと検証工数:アウト・オブ・オーダ実行や高精度な予測器は設計と検証を難しくする。
実装と検証
設計はRTL(ハードウェア記述言語)で記述され、シミュレーション・合成・タイミング解析・物理設計を経て製造される。検証はソフトウェア互換性(ISA準拠)、機能検証、パフォーマンス測定、消費電力評価など多層で行われる。近年は形式検証やプロパティチェック、自動テスト生成が重要になっている。
セキュリティとマイクロアーキテクチャ
スペクトルやメルトダウンといった脆弱性は、マイクロアーキテクチャの投機実行やキャッシュ動作を悪用するサイドチャネル攻撃の例であり、設計時にこれらを考慮することが不可欠になっている。対策はマイクロコードやハードウェア修正、OS側の緩和策などが組み合わされる。
代表的な例
同一ISAを使った異なるマイクロアーキテクチャの例:
- x86系:IntelのPentium系(P6、NetBurst、Core、Skylakeなど)やAMDのAthlon/Zenなど。各世代でパイプライン深度、キャッシュ構成、予測器、マルチスレッディングの実装が異なる。
- ARM系:ARMv8などのISAを、Cortex-Aシリーズや自社設計コアで異なるトレードオフで実装。
- RISC-V:オープンISAをベースに各社・研究機関が多様なマイクロアーキテクチャを開発している。
まとめ
マイクロアーキテクチャは、ISAが規定する機能をハードウェアで実現するための詳細な設計であり、性能・電力・コスト・設計期間といった要因を調整することで最終製品の特性を決める。ソフトウェアからは同じISAに見える複数の実装が存在し得るため、マイクロアーキテクチャはCPUの「中身」を決定する重要な層である。
用語の由来
命令セットアーキテクチャとの関係
マイクロアーキテクチャは、命令セットアーキテクチャと関係がありますが、同じではありません。命令セットアーキテクチャは、アセンブリ言語のプログラマやコンパイラの作者が見たプロセッサのプログラミングモデルに近く、実行モデル、プロセッサレジスタ、メモリアドレスモード、アドレスおよびデータフォーマットなどが含まれます。マイクロアーキテクチャ(またはコンピュータの構成)は主に低レベルの構造であるため、プログラミングモデルに隠れている多くの詳細を管理します。プロセッサの内部部品と、それらがどのように連携してアーキテクチャ仕様を実現するかを記述します。
マイクロアーキテクチャの要素は、単一の論理ゲートから、レジスタ、ルックアップテーブル、マルチプレクサ、カウンタなど、完全なALU、FPU、さらに大きな要素に至るまで、あらゆるものが含まれる可能性があります。電子回路レベルでは、実際の論理設計に加えて、どの基本的なゲート構築構造を使用するか、どのような論理実装タイプ(スタティック/ダイナミック、フェーズ数など)を選択するかなど、トランジスタレベルの詳細まで細分化することができる。
重要なポイントをいくつか紹介します。
- 1つのマイクロアーキテクチャ、特にマイクロコードを含む場合、コントロールストアを変更することで、多くの異なる命令セットを実装することができます。しかし、マイクロコードやROMやPLA内のテーブル構造によって簡略化されても、これは非常に複雑なものとなり得ます。
- 2つのマシンが同じマイクロアーキテクチャ、つまり同じブロック図を持っていても、ハードウェアの実装は全く異なる場合があります。これは、電子回路のレベルだけでなく、(ICやディスクリート部品の)製造の物理的なレベルも管理されています。
- マイクロアーキテクチャが異なるマシンは、同じ命令セットアーキテクチャを持つため、どちらも同じプログラムを実行することが可能である。新しいマイクロアーキテクチャや回路ソリューションと半導体製造の進歩により、新世代のプロセッサはより高い性能を達成することができます。
説明文の簡略化
マーケティングでよく使われる、非常に単純化された高レベルの説明では、バス幅などのかなり基本的な特性のみを示し、さまざまなタイプの実行ユニットや、分岐予測やキャッシュメモリなどの大規模システムを単純なブロックとして描き、おそらくいくつかの重要な属性や特性を記すことができます。また、パイプラインの構造(フェッチ、デコード、アサイン、実行、ライトバックなど)についての詳細が記載されている場合もあります。
マイクロアーキテクチャの側面
パイプライン型データパスは、現在のマイクロアーキテクチャで最もよく使われているデータパス設計です。この技術は、最新のマイクロプロセッサ、マイクロコントローラ、DSPのほとんどで使用されています。パイプラインアーキテクチャでは、アセンブリラインのように複数の命令が重なり合って実行されます。パイプラインには、マイクロアーキテクチャ設計の基本であるいくつかの異なるステージが含まれています。これらのステージには、命令フェッチ、命令デコード、実行、ライトバックなどがあります。一部のアーキテクチャでは、メモリアクセスなど他のステージも含まれています。パイプラインの設計は、マイクロアーキテクチャの中心的なタスクの1つです。
また、マイクロアーキテクチャには実行ユニットも欠かせません。実行ユニットには、算術論理演算ユニット(ALU)、浮動小数点演算ユニット(FPU)、ロード/ストアユニット、分岐予測などがある。これらのユニットは、プロセッサの演算や計算を実行する。実行ユニットの数、レイテンシ、スループットの選択は、マイクロアーキテクチャ設計の重要な課題である。また、システム内のメモリのサイズ、レイテンシ、スループット、接続性もマイクロアーキテクチャ上の決定事項です。
メモリコントローラなどの周辺機器を搭載するかどうかといったシステムレベルの設計判断も、マイクロアーキテクチャ設計プロセスの一部と考えることができます。これには、これらのペリフェラルの性能レベルや接続性についての決定も含まれます。
特定の性能レベルを主な目標とするアーキテクチャ設計とは異なり、マイクロアーキテクチャ設計では、他の制約条件に細心の注意を払います。以下のような問題に注意を払わなければならない。
- チップ面積/コスト。
- 消費電力
- ロジックの複雑さ。
- 接続のしやすさ。
- 製造可能性。
- デバッグのしやすさ
- テスト容易性。
マイクロアーキテクチャーコンセプト
一般に、すべてのCPU、シングルチップのマイクロプロセッサ、マルチチップの実装は、以下のステップを実行することによってプログラムを実行します。
- 命令を読み、それを解読する。
- 命令の処理に必要な関連データを検索する。
- インストラクションを処理する。
- 結果を書き出す。
この単純に見える一連のステップを複雑にしているのは、キャッシュ、メインメモリ、ハードディスクなどの不揮発性ストレージを含むメモリ階層(プログラムの命令やデータがある場所)が、常にプロセッサ本体より遅いという事実である。ステップ(2)では、データがコンピュータバス上に到着するまでの間に、しばしば遅延(CPU用語ではしばしば「ストール」と呼ばれる)が発生する。この遅延をできるだけなくすための設計が盛んに研究されてきた。長年にわたり、より多くの命令を並列に実行し、プログラムの実効速度を向上させることが設計の中心的な目標となってきた。そのため、複雑な論理構造、回路構造を採用した。かつては、このような技術は回路量が多いため、高価なメインフレームやスーパーコンピュータにしか実装できなかった。しかし、半導体の製造が進むにつれて、これらの技術を1つの半導体チップに実装できるようになりました。
以下では、最近のCPUに共通するマイクロアーキテクチャの技術についてサーベイします。
命令セット選択
どの命令セットアーキテクチャを使用するかの選択は、高性能デバイスの実装の複雑さに大きく影響します。長年にわたり、コンピュータ設計者は、命令セットの複雑さに設計者の労力と時間を費やすのではなく、性能を向上させる機能に設計者の労力と時間を費やすことで、より高性能な実装を可能にするために、命令セットの簡素化に全力を注いできたのです。
命令セット設計は、CISC型、RISC型、VLIW型、EPIC型と進歩してきた。データ並列を扱うアーキテクチャには、SIMDやベクターがある。
命令パイプライン化
性能向上のための最初の、そして最も強力なテクニックの1つが、命令パイプラインの使用です。初期のプロセッサ設計では、1つの命令に対して上記のすべてのステップを実行した後に次の命令に移っていました。例えば、命令のデコード回路は実行中にアイドル状態になるなど、プロセッサ回路の大部分はどのステップでもアイドル状態になっていた。
パイプラインは、多数の命令を同時に処理することで性能を向上させる。同じ基本的な例では、プロセッサは、最後の命令が結果を待っている間に、新しい命令のデコード(ステップ1)を開始することになる。これにより、一度に最大4つの命令が「飛行中」になり、プロセッサは4倍速く見えるようになる。1つの命令が完了するのにかかる時間は同じだが(それでも4つのステップがある)、CPU全体としては命令の「破棄」がはるかに速く、より高いクロック速度で動作させることができるのである。
キャッシュ
チップ製造技術の向上により、より多くの回路を同じチップに搭載できるようになり、設計者はその活用方法を模索し始めた。その中で、最も一般的な方法の1つが、増え続けるキャッシュメモリをオンチップに追加することであった。キャッシュは非常に高速なメモリで、メインメモリとのやり取りに比べれば、数サイクルでアクセスできるメモリである。CPUには、キャッシュの読み書きを自動化するキャッシュコントローラが搭載されており、データがすでにキャッシュにある場合は単に「表示」されるが、ない場合はキャッシュコントローラがデータを読み込む間、プロセッサは「停止」させられる。
RISCデザインは1980年代半ばから後半にかけてキャッシュを追加し始めましたが、多くの場合、合計でわずか4キロバイトでした。この数は時間とともに増加し、現在では一般的なCPUは約512KB、より強力なCPUは1、2、あるいは4、6、8、12MBを搭載し、複数のメモリ階層に編成されている。一般に、キャッシュが多いほど速度が上がると言われている。
キャッシュとパイプラインの相性は抜群だったのです。以前は、オフチップ・キャッシュメモリのアクセスレイテンシよりも高速に動作するパイプラインを構築することはあまり意味がなかったのです。代わりにオンチップのキャッシュメモリを使えば、パイプラインはキャッシュのアクセスレイテンシよりもはるかに短い時間で動作することができるのである。このため、プロセッサの動作周波数は、オフチップメモリの動作周波数よりもはるかに速い速度で向上させることができた。
分岐予測・投機実行
命令レベルの並列処理による性能向上を阻むのは、パイプラインのストールと分岐によるフラッシュです。プロセッサの命令デコーダが条件分岐命令に遭遇したことを確認してから、決定したジャンプレジスタの値を読み出すまでに、数サイクルの間パイプラインがストールする可能性がある。平均すると、実行される命令の5回に1回は分岐なので、失速の度合いも高い。さらに、分岐が行われた場合は、パイプラインにあった後続の命令をすべてフラッシュする必要があるため、さらに悪化する。
このような分岐ペナルティを軽減するために、分岐予測や投機的実行といった技術が使われている。分岐予測は、特定の分岐が行われるかどうかをハードウェアが経験的に推測するものです。この推測により、ハードウェアはレジスタの読み込みを待たずに命令をプリフェッチすることができる。投機的実行は、さらに強化されたもので、分岐を行うかどうかが判明する前に、予測されたパスに沿ったコードを実行するものである。
アウトオブオーダー実行
キャッシュを追加することで、メインメモリ階層からのデータ取り込み待ちによるストールの頻度や時間は減少しますが、ストールを完全になくすことはできません。初期の設計では、キャッシュミスが発生すると、キャッシュコントローラはプロセッサをストールさせて待機させることになります。もちろん、その時点でキャッシュ内のデータが利用可能な他の命令がプログラム内に存在する可能性もある。アウトオブオーダー実行は、古い命令がキャッシュで待機している間に、準備のできた命令を処理し、結果を並べ替えて、すべてがプログラムされた順序で起こったように見せかけるものである。
スーパースカラ
しかし、半導体の製造技術が向上し、より多くの論理ゲートを使用できるようになった。
上記の概要では、プロセッサは一度に1つの命令の一部を処理する。複数の命令を同時に処理できれば、コンピュータのプログラムはより高速に実行される。そこで、ALUなどの機能単位を複製して実現したのが、スーパースカラ型プロセッサである。機能単位の複製が可能になったのは、単一命令プロセッサの集積回路(「ダイ」と呼ばれることもある)面積が、確実に製造できる限界を超えなくなってからである。1980年代後半になると、スーパースカラ設計が市場に出回るようになった。
最近の設計では、2つのロードユニット、1つのストア(多くの命令は結果を保存しない)、2つ以上の整数演算ユニット、2つ以上の浮動小数点ユニット、そして多くの場合、ある種のSIMDユニットが見られるのが一般的です。命令発行ロジックは、メモリから膨大な命令リストを読み込んで、その時点でアイドル状態にあるさまざまな実行ユニットに引き渡すことで複雑さを増していく。そして、その結果は最後に集められ、再順序付けされる。
レジスタ名変更
レジスタ名変更とは、プログラム命令で同じレジスタを再利用することにより、不要な直列実行を避けるための技術である。同じレジスタを使用する命令群があった場合、一方の命令群を先に実行し、もう一方の命令群にレジスタを譲りますが、もう一方の命令群に別の類似したレジスタを割り当てれば、両方の命令群を並列に実行することができます。
マルチプロセッシングとマルチスレッド
CPUの動作周波数とDRAMのアクセス時間との差が大きくなり、1つのプログラム内で命令レベルの並列性(ILP)を高める技術では、メインメモリからのデータ取り込み時に発生する長いストール(遅延)を克服することはできなかった。また、より高度なILP技術に必要なトランジスタ数の多さと動作周波数の高さは、もはや安価に冷却できないレベルの電力損失を必要とした。こうした理由から、新しい世代のコンピューターでは、単一のプログラムやプログラムスレッドの外側に存在する、より高度な並列処理を利用するようになったのです。
この流れは「スループットコンピューティング」と呼ばれることもあります。この考え方は、メインフレーム市場でオンライントランザクション処理が、1つのトランザクションの実行速度だけでなく、同時に大量のトランザクションを処理する能力を重視していたことに端を発しています。ネットワーク・ルーティングやWebサイト・サービスのようなトランザクション・ベースのアプリケーションがここ10年で大幅に増加したため、コンピュータ業界は容量とスループットの問題を再び強調するようになりました。
この並列性を実現する手法の一つが、複数のCPUを搭載したコンピュータシステムであるマルチプロセッシングシステムです。かつてはハイエンドのメインフレームに限られていたが、現在では小規模(2〜8個)マルチプロセッサのサーバーが中小企業市場向けに一般的になっている。大企業では、大規模(16〜256個)マルチプロセッサーが一般的である。パソコンでも、1990年代からマルチCPUのものが登場している。
半導体技術の進歩によりトランジスタのサイズが小さくなり、複数のCPUを同一シリコンチップ上に実装したマルチコアCPUが登場した。当初は、よりシンプルで小型のCPUを搭載することで、1つのシリコンチップに複数のCPUを搭載できる組み込み市場をターゲットとしたチップで使用されていた。2005年には、半導体技術により、デュアルハイエンド・デスクトップCPUのCMPチップの大量生産が可能になった。UltraSPARC T1のように、1つのシリコンに多くのプロセッサを搭載するために、よりシンプルな(スカラー、インオーダー)設計を採用しているものもある。
また、最近では、マルチスレッドという手法も普及している。マルチスレッドでは、プロセッサが低速なシステムメモリからデータを取得する必要がある場合、データの到着を待つ代わりに、プロセッサは実行準備が整った別のプログラムやプログラムスレッドに切り替わります。これは、特定のプログラム/スレッドを高速化するわけではありませんが、CPUがアイドル状態である時間を短縮することで、システム全体のスループットを向上させることができます。
概念的には、マルチスレッドはOSレベルでのコンテキストスイッチと同じです。違いは、マルチスレッドCPUは、通常コンテキストスイッチが必要とする数百、数千のCPUサイクルの代わりに、1CPUサイクルでスレッドスイッチを行なえることです。これは、アクティブなスレッドごとに状態ハードウェア(レジスタファイルやプログラムカウンタなど)を複製することで実現されている。
さらに強化されたのが、同時マルチスレッドです。この技術により、スーパースカラCPUは同じサイクルで異なるプログラム/スレッドの命令を同時に実行することができるようになります。
関連ページ
- マイクロプロセッサー
- マイクロコントローラ
- マルチコアプロセッサー
- デジタルシグナルプロセッサ
- CPU設計
- データパス
- 命令レベル並列処理(ILP)
質問と回答
Q:マイクロアーキテクチャとは何ですか?
A:マイクロアーキテクチャとは、コンピュータ、中央処理装置、デジタル信号プロセッサの電気回路について、ハードウェアの動作を完全に記述するのに十分な記述のことです。
Q:学者たちはこの概念をどのように呼んでいるのですか?
A:学者たちは、マイクロアーキテクチャに言及するとき、「コンピュータ組織」という言葉を使います。
Q:コンピュータ業界では、この概念をどのように呼んでいるのですか?
A:コンピュータ業界では、この概念を指す場合、「マイクロアーキテクチャ」と言うことが多いようです。
Q:コンピュータ・アーキテクチャを構成する2つの分野は何ですか?
A:マイクロアーキテクチャと命令セットアーキテクチャ(ISA)を合わせて、コンピュータ・アーキテクチャと呼びます。
Q:ISAとは何の略ですか?
A:ISAは、Instruction Set Architectureの略です。
Q:μarchとは何の略ですか?A:μArchはMicroarchitectureの略です。
関連項目
著者
AlegsaOnline.com マイクロアーキテクチャとは?定義と仕組み—CPU動作と命令セット(ISA)の関係 Leandro Alegsa
URL: https://ja.alegsaonline.com/art/64586
出典
- computer.org : IEEE Computer Society
- extremetech.com : PC Processor Microarchitecture